Comprendre et interpréter une analyse PLS-SEM
Du modèle de mesure aux liens structurels : un guide exhaustif illustré par des résultats réels, conçu pour les non-spécialistes.
- La logique d’ensemble du PLS-SEM
- Étape 1 — Les saturations (Loadings)
- Étape 2 — La fiabilité (Alpha & CR)
- Étape 3 — La validité convergente (AVE)
- Étape 4 — La validité discriminante
- Étape 5 — La colinéarité (VIF)
- Étape 6 — Les liens structurels (β, t, p)
- Étape 7 — La taille de l’effet (f²)
- Étape 8 — Le pouvoir explicatif (R²)
- Étape 9 — La pertinence prédictive (Q² & PLSpredict)
- Étape 10 — Le fit global (SRMR)
- Synthèse des résultats
- Bibliographie
La logique d’ensemble du PLS-SEM
Avant de plonger dans les indicateurs, il faut comprendre ce qu’on cherche à faire avec une analyse PLS-SEM. Imaginez que vous souhaitez étudier un phénomène complexe — par exemple, comprendre pourquoi un client accepte ou refuse d’interagir avec un robot dans un hôtel. Ce phénomène n’est pas directement observable : on ne peut pas mesurer “l’intention d’usage” comme on mesure la température. On peut en revanche poser plusieurs questions à des répondants, et synthétiser leurs réponses en un score global.
Ces scores synthétiques sont appelés variables latentes (ou “construits”). Le PLS-SEM (Partial Least Squares – Structural Equation Modeling), traduit en français par « modélisation par équations structurelles par moindres carrés partiels », fait deux choses simultanément (Hair et al., 2019) :
- Il mesure si vos questions reflètent fidèlement les concepts qu’elles sont censées capturer (modèle de mesure).
- Il teste si ces concepts exercent bien des effets les uns sur les autres, conformément à vos hypothèses (modèle structurel).
Pensez à un médecin qui mesure la santé d’un patient. Il ne peut pas “voir” la santé directement — il prend la tension, analyse les prises de sang, mesure le pouls. Chaque mesure est un indicateur du concept “santé”. Le PLS-SEM vérifie d’abord que vos indicateurs sont bons (modèle de mesure), puis que vos concepts sont bien reliés entre eux (modèle structurel).
Dans notre étude, on cherche à expliquer l’Intention d’usage d’un robot humanoïde. Les variables explicatives sont : l’Anthropomorphisme, l’Utilité perçue, le Plaisir perçu, le Risque Vie Privée, le Risque Psychologique, le Risque de Déshumanisation et le Risque pour l’Emploi. Chacune de ces variables est mesurée par plusieurs questions (items) sur une échelle de 1 à 5.
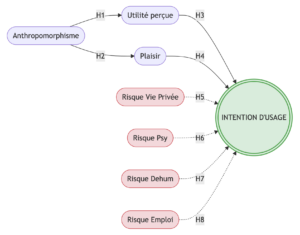
L’analyse se déroule en deux grandes phases, elles-mêmes subdivisées en plusieurs étapes :
On vérifie que les questions posées mesurent bien les bons concepts. C’est comme vérifier que votre thermomètre mesure bien la température et non autre chose.
On teste les liens de causalité entre les concepts. C’est comme vérifier que la fièvre est bien causée par une infection, et non l’inverse.
Étape 1 — Les saturations (Loadings)
La première question à se poser est : chaque question (item) est-elle bien représentative du concept qu’elle est censée mesurer ? En PLS-SEM, on répond à cette question en calculant les saturations factorielles (ou loadings en anglais), notées λ (lambda).
Un loading mesure la corrélation entre une question et le score global du concept auquel elle appartient. Il prend une valeur entre -1 et 1. Plus il est proche de 1, plus la question est une bonne représentante du concept (Hair et al., 2019 ; Fornell & Larcker, 1981).
Le loading répond à cette question : si je prends la réponse d’un individu à cette question, dans quelle mesure est-elle représentative de son score global sur ce concept ? Un loading de 0,85 signifie que la question “partage” 85% de son information avec le concept global.
Un loading est acceptable s’il est ≥ 0,70 (Hair et al., 2019). Certains auteurs tolèrent 0,60 dans des recherches exploratoires (Churchill, 1979). En dessous de 0,40, l’item doit être supprimé du modèle car il apporte plus de bruit que d’information.
Nos résultats — Loadings des items
| Construit | Item | Loading (λ) | Évaluation |
|---|---|---|---|
| Anthropomorphisme | ANT1 | 0,871 | ✓ Excellent |
| ANT2 | 0,866 | ✓ Excellent | |
| ANT3 | 0,813 | ✓ Très bon | |
| ANT4 | 0,824 | ✓ Très bon | |
| ANT5 | 0,712 | ✓ Acceptable | |
| Utilité perçue | UTIL1 | 0,799 | ✓ Bon |
| UTIL2 | 0,841 | ✓ Très bon | |
| UTIL3 | 0,793 | ✓ Bon | |
| UTIL4 | 0,825 | ✓ Très bon | |
| UTIL5 | 0,711 | ✓ Acceptable | |
| UTIL6 | 0,753 | ✓ Bon | |
| UTIL7 | 0,641 | ⚠ Limite | |
| Plaisir perçu | PLAIS1 | 0,863 | ✓ Excellent |
| PLAIS2 | 0,836 | ✓ Très bon | |
| PLAIS3 | 0,793 | ✓ Bon | |
| PLAIS4 | 0,915 | ✓ Excellent | |
| Risque Vie Privée | RCONTETH1 | 0,865 | ✓ Excellent |
| RCONTETH2 | 0,767 | ✓ Bon | |
| RCONTETH3 | 0,873 | ✓ Excellent | |
| RCONTETH4 | 0,766 | ✓ Bon | |
| Risque Psy | RPSY1 | 0,883 | ✓ Excellent |
| RPSY2 | 0,879 | ✓ Excellent | |
| RPSY3 | 0,902 | ✓ Excellent | |
| Risque Déshumanisation | RDEHUM1 | 0,839 | ✓ Très bon |
| RDEHUM2 | 0,856 | ✓ Excellent | |
| RDEHUM3 | 0,798 | ✓ Bon | |
| RDEHUM4 | 0,882 | ✓ Excellent | |
| RDEHUM5 | 0,836 | ✓ Très bon | |
| Risque Emploi | RPEMP1 | 0,770 | ✓ Bon |
| RPEMP2 | 0,860 | ✓ Excellent | |
| RPEMP3 | 0,787 | ✓ Bon | |
| RPEMP4 | 0,801 | ✓ Bon | |
| RPEMP5 | 0,885 | ✓ Excellent | |
| Intention d’usage | INT1 | 0,918 | ✓ Excellent |
| INT2 | 0,856 | ✓ Excellent | |
| INT3 | 0,888 | ✓ Excellent | |
| INT4 | 0,883 | ✓ Excellent |
Tableau 1 — Saturations factorielles (loadings) de tous les items. Seuil requis : ≥ 0,70.
Verdict : La quasi-totalité des items présente un loading ≥ 0,70. L’item UTIL7 (loading = 0,641) se situe en dessous du seuil recommandé mais reste acceptable dans un contexte exploratoire. Le modèle de mesure est solide. Chaque question est bien représentative du concept qu’elle mesure.
Étape 2 — La fiabilité (Alpha de Cronbach & Fiabilité Composite)
Une fois que chaque question est bien représentative de son concept, on vérifie que l’ensemble des questions d’un même bloc forment un tout cohérent. C’est ce qu’on appelle la fiabilité de l’échelle. On utilise deux indicateurs complémentaires.
L’Alpha de Cronbach (α)
Proposé par Cronbach en 1951, l’Alpha est l’indicateur de fiabilité le plus connu. Il mesure l’homogénéité interne d’un groupe de questions : est-ce que toutes les questions du bloc mesurent bien la même chose, dans le même sens ? Concrètement, il regarde si les répondants ont tendance à répondre de manière similaire à toutes les questions d’un même bloc (Cronbach, 1951).
L’Alpha varie de 0 à 1. Un Alpha de 0,90 signifie que 90% de la variabilité des réponses est due au concept mesuré (et seulement 10% à des erreurs de mesure). En pratique : α ≥ 0,70 = acceptable · α ≥ 0,80 = bon · α ≥ 0,90 = excellent (Nunnally, 1978).
La Fiabilité Composite (CR)
La Fiabilité Composite (Composite Reliability, CR) est un indicateur plus moderne, recommandé par Hair et al. (2019) en complément de l’Alpha. Contrairement à l’Alpha qui traite toutes les questions de la même façon, la CR accorde plus d’importance aux questions qui ont un loading plus élevé (c’est-à-dire aux questions les plus représentatives du concept). Elle est donc plus précise et moins sensible au nombre d’items dans le bloc (Ringle et al., 2015).
Alpha de Cronbach : ≥ 0,70 (minimum), idéalement ≥ 0,80 — Fiabilité Composite (CR) : ≥ 0,70 (minimum), idéalement ≥ 0,80. Un CR supérieur à 0,95 peut toutefois signaler que les items sont redondants (Hair et al., 2019).
Nos résultats — Fiabilité des construits
| Construit | Alpha de Cronbach (α) | Éval. Alpha | Fiabilité Composite (CR) | Éval. CR |
|---|---|---|---|---|
| Anthropomorphisme | 0,876 | ✓ Bon | 0,910 | ✓ Excellent |
| Utilité perçue | 0,883 | ✓ Bon | 0,910 | ✓ Excellent |
| Plaisir perçu | 0,874 | ✓ Bon | 0,914 | ✓ Excellent |
| Risque Vie Privée | 0,839 | ✓ Bon | 0,891 | ✓ Bon |
| Risque Psy | 0,867 | ✓ Bon | 0,918 | ✓ Excellent |
| Risque Déshumanisation | 0,898 | ✓ Bon | 0,924 | ✓ Excellent |
| Risque Emploi | 0,882 | ✓ Bon | 0,912 | ✓ Excellent |
| Intention d’usage | 0,909 | ✓ Excellent | 0,936 | ✓ Excellent |
Tableau 2 — Fiabilité des construits. Seuil minimum : Alpha ≥ 0,70 · CR ≥ 0,70.
Verdict : Tous les construits dépassent largement les seuils minimaux requis. L’Alpha de Cronbach varie de 0,839 à 0,909 et la Fiabilité Composite de 0,891 à 0,936. La fiabilité interne de l’ensemble des échelles est excellente : chaque groupe de questions forme un bloc cohérent mesurant bien son concept.
Étape 3 — La validité convergente (AVE)
On sait maintenant que les questions d’un même bloc sont cohérentes entre elles. Mais il faut aller plus loin : le concept capture-t-il bien l’essentiel de l’information contenue dans ses questions ? C’est l’objet de la validité convergente, mesurée par l’AVE (Average Variance Extracted — Variance Moyenne Extraite).
L’AVE calcule, en moyenne, quelle proportion de la variabilité des réponses aux questions est expliquée par le concept latent, et quelle proportion est due à des erreurs de mesure (Fornell & Larcker, 1981). C’est un peu comme demander : “Parmi tout ce que mesurent ces questions, quelle part est vraiment ce qu’on veut mesurer (signal), et quelle part est du bruit ?”
AVE = moyenne des loadings² de toutes les questions du bloc. Si AVE = 0,67, cela signifie que 67% de la variance des items est expliquée par le concept, et seulement 33% est due à des erreurs de mesure. Le signal domine le bruit.
L’AVE doit être ≥ 0,50. En dessous de ce seuil, plus de la moitié de la variance des items est due aux erreurs de mesure plutôt qu’au concept : l’échelle capte plus de bruit que de signal.
Nos résultats — Validité convergente
| Construit | AVE | Évaluation | Interprétation |
|---|---|---|---|
| Anthropomorphisme | 0,671 | ✓ Bon | 67,1% du signal capturé |
| Utilité perçue | 0,591 | ✓ Acceptable | 59,1% du signal capturé |
| Plaisir perçu | 0,727 | ✓ Excellent | 72,7% du signal capturé |
| Risque Vie Privée | 0,671 | ✓ Bon | 67,1% du signal capturé |
| Risque Psy | 0,789 | ✓ Excellent | 78,9% du signal capturé |
| Risque Déshumanisation | 0,710 | ✓ Bon | 71,0% du signal capturé |
| Risque Emploi | 0,675 | ✓ Bon | 67,5% du signal capturé |
| Intention d’usage | 0,786 | ✓ Excellent | 78,6% du signal capturé |
Tableau 3 — Variance Moyenne Extraite (AVE). Seuil requis : ≥ 0,50.
Verdict : Tous les construits dépassent largement le seuil de 0,50. L’AVE varie de 0,591 (Utilité) à 0,789 (Risque Psy). La validité convergente est établie pour l’ensemble du modèle : les questions mesurent bien les concepts auxquels elles appartiennent.
Étape 4 — La validité discriminante (Fornell-Larcker & HTMT)
On a vérifié que chaque concept est bien mesuré par ses propres questions. Il faut maintenant s’assurer que les différents concepts sont bien distincts les uns des autres. Si “Plaisir” et “Utilité” sont trop similaires dans l’esprit des répondants, ils ne constituent pas vraiment deux concepts séparés, et le modèle perd sa signification.
C’est l’objet de la validité discriminante. On utilise deux critères complémentaires et de rigueur croissante (Henseler, Ringle & Sarstedt, 2015).
Le critère de Fornell-Larcker
Proposé en 1981, ce critère compare, pour chaque variable, la racine carrée de son AVE aux corrélations qu’elle entretient avec les autres variables. La logique est simple : un concept doit partager plus de variance avec ses propres items qu’avec n’importe quel autre concept. En d’autres termes, √AVE doit être supérieur à toutes les corrélations inter-construits de la colonne (Fornell & Larcker, 1981).
Dans la matrice ci-dessous, les valeurs en diagonale représentent la racine carrée de l’AVE de chaque construit (ce sont les valeurs les plus grandes de chaque colonne, ce qui est bon signe). Les valeurs hors diagonale représentent les corrélations entre construits.
| Construit | ANT | UTIL | PLAIS | RVP | RPSY | RDEH | REMP | INT |
|---|---|---|---|---|---|---|---|---|
| Anthropomorphisme | 0,819 | 0,673 | 0,720 | -0,230 | -0,306 | -0,197 | -0,097 | 0,684 |
| Utilité perçue | 0,673 | 0,769 | 0,760 | -0,276 | -0,392 | -0,196 | -0,170 | 0,786 |
| Plaisir perçu | 0,720 | 0,760 | 0,853 | -0,297 | -0,503 | -0,295 | -0,208 | 0,866 |
| Risque Vie Privée | -0,230 | -0,276 | -0,297 | 0,819 | 0,686 | 0,665 | 0,672 | -0,392 |
| Risque Psy | -0,306 | -0,392 | -0,503 | 0,686 | 0,888 | 0,663 | 0,615 | -0,533 |
| Risque Déshumanisation | -0,197 | -0,196 | -0,295 | 0,665 | 0,663 | 0,843 | 0,768 | -0,308 |
| Risque Emploi | -0,097 | -0,170 | -0,208 | 0,672 | 0,615 | 0,768 | 0,822 | -0,282 |
| Intention d’usage | 0,684 | 0,786 | 0,866 | -0,392 | -0,533 | -0,308 | -0,282 | 0,887 |
Tableau 4 — Matrice Fornell-Larcker. Les valeurs en vert (diagonale) sont les √AVE. Elles doivent être supérieures à toutes les corrélations de leur colonne/ligne.
Le critère HTMT (Heterotrait-Monotrait Ratio)
Le HTMT est le test le plus rigoureux et le plus récent de la validité discriminante (Henseler et al., 2015). Il est désormais recommandé en priorité dans la littérature PLS-SEM. Son principe : si deux concepts sont vraiment distincts, alors la corrélation entre eux (hétérotraits) doit être significativement plus faible que la corrélation interne à chacun d’eux (monotraits).
Un HTMT < 0,85 est le critère strict (Gold, Malhotra & Segars, 2001). Certains auteurs tolèrent jusqu’à < 0,90 pour des construits conceptuellement proches (Henseler et al., 2015). Au-delà, les deux concepts se confondent dans l’esprit des répondants.
| Construit | ANT | UTIL | PLAIS | RVP | RPSY | RDEH | REMP | INT |
|---|---|---|---|---|---|---|---|---|
| Anthropomorphisme | 1,000 | 0,758 | 0,815 | 0,260 | 0,345 | 0,216 | 0,105 | 0,764 |
| Utilité perçue | 0,758 | 1,000 | 0,853 | 0,301 | 0,442 | 0,206 | 0,169 | 0,868 |
| Plaisir perçu | 0,815 | 0,853 | 1,000 | 0,328 | 0,576 | 0,322 | 0,212 | 0,968 |
| Risque Vie Privée | 0,260 | 0,301 | 0,328 | 1,000 | 0,787 | 0,758 | 0,745 | 0,432 |
| Risque Psy | 0,345 | 0,442 | 0,576 | 0,787 | 1,000 | 0,750 | 0,682 | 0,599 |
| Risque Déshumanisation | 0,216 | 0,206 | 0,322 | 0,758 | 0,750 | 1,000 | 0,855 | 0,338 |
| Risque Emploi | 0,105 | 0,169 | 0,212 | 0,745 | 0,682 | 0,855 | 1,000 | 0,294 |
| Intention d’usage | 0,764 | 0,868 | 0,968 | 0,432 | 0,599 | 0,338 | 0,294 | 1,000 |
Tableau 5 — Matrice HTMT. Seuil strict : < 0,85. Seuil toléré : < 0,90. Les valeurs en orange sont à surveiller.
Deux valeurs HTMT méritent attention. Le HTMT entre Plaisir et Intention atteint 0,968, ce qui suggère que ces deux construits sont très proches — le plaisir ressenti lors de l’interaction avec un robot est fortement associé à l’intention de l’utiliser, à tel point que les frontières conceptuelles s’amincissent. De même, le HTMT entre Risque Déshumanisation et Risque Emploi est de 0,855, légèrement au-dessus du seuil strict de 0,85. Ces résultats invitent à la prudence dans l’interprétation, et suggèrent que des études futures pourraient explorer la fusion potentielle de ces construits ou leur clarification conceptuelle. Dans le cadre de cette étude, ces valeurs restent tolérées au regard de la proximité théorique attendue.
Étape 5 — La colinéarité (VIF)
Avant de tester les liens entre les concepts, il faut s’assurer qu’aucun prédicteur ne fait “double emploi” avec un autre. Quand deux variables explicatives sont trop corrélées entre elles, le modèle ne parvient plus à démêler leurs effets respectifs sur la variable dépendante. C’est le problème de la multicolinéarité (Hair et al., 2019).
On la mesure par le VIF (Variance Inflation Factor), ou Facteur d’Inflation de la Variance. Intuitivement, le VIF indique de combien de fois la variance estimée du coefficient d’un prédicteur est “gonflée” par sa corrélation avec les autres prédicteurs (O’Brien, 2007).
Imaginez deux témoins qui ont tout vu ensemble et racontent la même histoire. Impossible de savoir ce que chacun apporte de nouveau. Le VIF mesure à quel point chaque variable “raconte une histoire déjà racontée” par une autre variable du modèle.
VIF < 5 : pas de problème (Hair et al., 2019). VIF < 3 : idéal. VIF ≥ 10 : problème sévère, les résultats ne sont pas fiables. Un VIF = 1 signifie qu’il n’y a aucune colinéarité.
Nos résultats — VIF du modèle structurel
| Variable dépendante | Prédicteur | VIF | Évaluation |
|---|---|---|---|
| Utilité perçue | Anthropomorphisme | 1,000 | ✓ Parfait (pas de colinéarité) |
| Plaisir perçu | Anthropomorphisme | 1,000 | ✓ Parfait |
| Intention d’usage | Plaisir perçu | 2,778 | ✓ Acceptable |
| Utilité perçue | 2,429 | ✓ Acceptable | |
| Risque Vie Privée | 2,432 | ✓ Acceptable | |
| Risque Psy | 2,713 | ✓ Acceptable | |
| Risque Déshumanisation | 2,968 | ✓ Acceptable | |
| Risque Emploi | 2,825 | ✓ Acceptable |
Tableau 6 — VIF des prédicteurs. Seuil requis : < 5. Idéalement < 3.
Verdict : Tous les VIF sont inférieurs à 3, avec un maximum de 2,968 (Risque Déshumanisation). Il n’y a aucun problème de multicolinéarité dans ce modèle. Chaque prédicteur apporte une contribution distincte et les coefficients estimés sont stables et fiables.
Étape 6 — Les liens structurels (β, t-value, p-value)
On entre maintenant dans le cœur du modèle structurel : les liens de causalité entre les concepts. Pour chaque flèche du modèle (ex : “Anthropomorphisme → Utilité perçue”), on estime trois indicateurs : le coefficient path (β), la t-value et la p-value.
Le coefficient path (β)
Le coefficient β (bêta standardisé) est la mesure de l’intensité et du sens du lien entre deux variables. Un β positif indique que quand le prédicteur augmente, la variable dépendante augmente aussi. Un β négatif indique l’inverse. Plus β est proche de ±1, plus le lien est fort (Hair et al., 2019).
|β| > 0,50 = lien fort · 0,20 ≤ |β| ≤ 0,50 = lien modéré · |β| < 0,20 = lien faible (Chin, 1998). Un β négatif signifie un effet d’inhibition (plus X augmente, moins Y est élevé).
La t-value et le bootstrapping
En PLS-SEM, on ne peut pas calculer directement la significativité statistique d’un coefficient par des formules analytiques (contrairement à la régression classique). On utilise une technique de rééchantillonnage appelée bootstrapping : le modèle est réestimé des centaines de fois sur des sous-échantillons aléatoires de vos données (ici 500 fois). Cette procédure génère une distribution empirique des coefficients, qui permet de calculer un écart-type et donc une t-value (Hair et al., 2019).
La t-value est le ratio entre le coefficient β et son écart-type bootstrap. Plus elle est grande, plus le résultat est stable et reproductible. Une t-value ≥ 1,96 correspond à un niveau de confiance de 95% (seuil habituel en sciences sociales).
La p-value
La p-value est la probabilité d’obtenir un résultat au moins aussi extrême si le lien était en réalité nul. Une p-value de 0,03 signifie qu’il y a seulement 3% de chances que ce résultat soit dû au hasard (Cohen, 1992). On accepte généralement : p < 0,05 (significatif au seuil de 5%), p < 0,01 (très significatif), p < 0,001 (hautement significatif).
Une hypothèse est validée si t-value ≥ 1,96 ET p-value < 0,05 (Hair et al., 2019). Ces deux critères doivent être remplis simultanément.
Nos résultats — Coefficients structurels
| Hyp. | Lien testé | β | t-value | p-value | Significatif ? |
|---|---|---|---|---|---|
| H1 | Anthropomorphisme → Utilité | +0,673 | 14,885 | 1,53e-28 | ✓ Oui (p<0,001) |
| H2 | Anthropomorphisme → Plaisir | +0,720 | 17,469 | 3,40e-34 | ✓ Oui (p<0,001) |
| H3 | Plaisir → Intention | +0,599 | 10,006 | 4,90e-24 | ✓ Oui (p<0,001) |
| H4 | Utilité → Intention | +0,281 | 4,559 | 2,38e-08 | ✓ Oui (p<0,001) |
| H5 | Risque Vie Privée → Intention | -0,104 | 2,087 | 0,033 | ✓ Oui (p<0,05) |
| H6 | Risque Psy → Intention | -0,068 | 1,206 | 0,185 | ✗ Non (p=0,185) |
| H7 | Risque Déshumanisation → Intention | +0,087 | 1,661 | 0,105 | ✗ Non (p=0,105) |
| H8 | Risque Emploi → Intention | -0,065 | 1,161 | 0,215 | ✗ Non (p=0,215) |
Tableau 7 — Coefficients structurels bootstrappés (n=500). Seuils : t > 1,96 et p < 0,05.
Lecture des résultats : Les quatre premières hypothèses sont solidement validées. L’Anthropomorphisme est un prédicteur très fort de l’Utilité (β=+0,673) et du Plaisir (β=+0,720). Le Plaisir est le prédicteur dominant de l’Intention (β=+0,599), suivi de l’Utilité (β=+0,281). Le Risque Vie Privée a un effet négatif significatif mais faible (β=-0,104). En revanche, les risques psychologique, de déshumanisation et d’emploi ne parviennent pas à démontrer un effet significatif sur l’intention d’usage une fois contrôlés les autres facteurs.
Étape 7 — La taille de l’effet (f²)
Un résultat peut être statistiquement significatif sans être pratiquement important. La significativité dépend notamment de la taille de l’échantillon : avec un très grand échantillon, même un effet infinitésimal sera significatif. La taille de l’effet f² (f-carré) permet de répondre à la question : “Quand on retire ce prédicteur du modèle, dans quelle mesure la capacité explicative du modèle se dégrade-t-elle ?” (Cohen, 1988).
Concrètement, f² compare le R² du modèle avec et sans chaque prédicteur. Plus le f² est élevé, plus le prédicteur contribue substantiellement à expliquer la variable dépendante.
f² ≥ 0,02 = effet petit · f² ≥ 0,15 = effet moyen · f² ≥ 0,35 = effet large.
| Variable dépendante | Prédicteur | f² | Taille de l’effet |
|---|---|---|---|
| Utilité perçue | Anthropomorphisme | 0,828 | ✓ Très large |
| Plaisir perçu | Anthropomorphisme | 1,076 | ✓ Très large |
| Intention d’usage | Plaisir perçu | 0,674 | ✓ Très large |
| Utilité perçue | 0,170 | ✓ Moyen | |
| Risque Vie Privée | 0,023 | → Petit | |
| Risque Psy | 0,009 | → Négligeable | |
| Risque Déshumanisation | 0,013 | → Négligeable | |
| Risque Emploi | 0,008 | → Négligeable |
Tableau 8 — Taille de l’effet f². Interprétation selon Cohen (1988).
Verdict : L’Anthropomorphisme exerce un effet très large sur l’Utilité (f²=0,828) et le Plaisir (f²=1,076). Le Plaisir a un effet très large sur l’Intention (f²=0,674). L’Utilité a un effet moyen (f²=0,170). En revanche, les quatre variables de risque ont des effets pratiquement négligeables à petits sur l’Intention d’usage, ce qui confirme et nuance les résultats sur la significativité.
Étape 8 — Le pouvoir explicatif du modèle (R²)
Le R² (coefficient de détermination) mesure la proportion de variance d’une variable dépendante que le modèle parvient à expliquer. Si R² = 0,808 pour l’Intention d’usage, cela signifie que 80,8% des variations d’Intention entre les répondants sont expliquées par les variables incluses dans le modèle. Les 19,2% restants sont dus à des facteurs non pris en compte (Hair et al., 2019).
R² ≥ 0,75 = substantiel · R² ≥ 0,50 = modéré · R² ≥ 0,25 = faible (Hair et al., 2019). En sciences sociales, un R² de 0,50 est déjà considéré comme très satisfaisant, car le comportement humain est intrinsèquement complexe et variable.
| Variable endogène | R² (In-Sample) | Évaluation |
|---|---|---|
| Utilité perçue | 0,453 | → Modéré à bon |
| Plaisir perçu | 0,518 | ✓ Modéré (bon) |
| Intention d’usage | 0,808 | ✓ Substantiel |
Tableau 9 — Coefficient de détermination R². Seuils : > 0,25 faible · > 0,50 modéré · > 0,75 substantiel.
Verdict : Le modèle explique 80,8% de la variance de l’Intention d’usage — un résultat exceptionnel pour une étude comportementale en sciences de gestion. L’Anthropomorphisme explique 45,3% de l’Utilité et 51,8% du Plaisir, ce qui confirme son rôle pivot dans le modèle.
Étape 9 — La pertinence prédictive (Q² et PLSpredict)
Le R² mesure à quel point le modèle s’ajuste aux données observées. Mais un modèle peut très bien “apprendre par cœur” les données sans être capable de prédire de nouvelles observations. La pertinence prédictive mesure cette capacité de généralisation (Shmueli et al., 2019).
Le Q² (Relevance Prédictive Structurelle)
Le Q² est calculé par validation croisée (10-fold cross-validation) : on divise les données en 10 blocs, on entraîne le modèle sur 9 blocs et on teste sur le 10ème, puis on recommence pour chaque bloc. Le Q² compare l’erreur de prédiction du modèle à une prédiction naïve (qui prédirait simplement la moyenne pour tout le monde). Si Q² > 0, le modèle prédit mieux que la moyenne — il a donc une vraie valeur prédictive (Stone, 1974 ; Geisser, 1975).
Q² > 0 = pertinence prédictive établie · Q² > 0,25 = pertinence moyenne · Q² > 0,50 = pertinence élevée (Hair et al., 2019).
| Variable endogène | R² (In-Sample) | Q² (Out-of-Sample) | Évaluation |
|---|---|---|---|
| Utilité perçue | 0,453 | 0,437 | ✓ Pertinence élevée |
| Plaisir perçu | 0,518 | 0,511 | ✓ Pertinence élevée |
| Intention d’usage | 0,808 | 0,791 | ✓ Pertinence très élevée |
Tableau 10 — R² et Q² comparés. La faible différence entre R² et Q² indique un modèle robuste sans sur-ajustement.
PLSpredict — Prédiction au niveau des items
PLSpredict va encore plus loin : il évalue la capacité prédictive item par item pour la variable cible (ici l’Intention). Pour chaque item de la variable Intention, il compare l’erreur de prédiction du modèle PLS (RMSE PLS) à celle d’un modèle de référence qui prédirait simplement la moyenne (RMSE naïf). Si RMSE PLS < RMSE naïf, le modèle prédit mieux que la prédiction par la moyenne (Shmueli et al., 2019).
| Item cible | RMSE Modèle PLS | RMSE Naïf (moyenne) | Q²_predict | Pouvoir prédictif |
|---|---|---|---|---|
| INT1 | 0,759 | 1,211 | 0,607 | ✓ Fort |
| INT2 | 0,909 | 1,309 | 0,518 | ✓ Fort |
| INT3 | 0,788 | 1,134 | 0,517 | ✓ Fort |
| INT4 | 0,617 | 1,374 | 0,799 | ✓ Fort |
Tableau 11 — PLSpredict sur les items d’Intention. RMSE Modèle < RMSE Naïf pour tous les items = pouvoir prédictif fort.
Verdict : Le modèle présente une pertinence prédictive très élevée. Le Q² de l’Intention (0,791) est très proche du R² (0,808), ce qui indique une généralisation excellente et l’absence de sur-apprentissage. PLSpredict confirme que les 4 items de l’Intention sont tous mieux prédits par le modèle que par la simple moyenne : le modèle a donc une réelle valeur prédictive, et pas seulement descriptive.
Étape 10 — Le fit global du modèle (SRMR)
Tous les indicateurs vus jusqu’ici évaluent des aspects spécifiques du modèle. Le SRMR (Standardized Root Mean Square Residual) est un indicateur global qui évalue dans quelle mesure la structure de corrélations prédite par le modèle correspond à la structure de corrélations réellement observée dans les données (Henseler et al., 2014).
Il calcule la différence moyenne entre les corrélations observées (ce que disent vraiment les données) et les corrélations implicites du modèle (ce que le modèle “dit” qu’elles devraient être). Plus cette différence est petite, meilleur est l’ajustement global.
SRMR < 0,08 = ajustement excellent · SRMR < 0,10 = ajustement acceptable · SRMR ≥ 0,10 = ajustement insuffisant (Hu & Bentler, 1999 ; Henseler et al., 2014).
| Indicateur | Valeur obtenue | Seuil idéal | Seuil acceptable | Statut |
|---|---|---|---|---|
| SRMR Global | 0,063 | < 0,08 | < 0,10 | ✓ Excellent |
Tableau 12 — Fit global SRMR. Une valeur de 0,063 indique un ajustement excellent du modèle aux données.
Verdict : Avec un SRMR de 0,063, bien en dessous du seuil critique de 0,08, le modèle présente un ajustement global excellent. La structure théorique proposée correspond très bien à la réalité observée dans les données.
Synthèse globale des résultats
Bilan du modèle de mesure
| Critère | Seuil requis | Résultat | Verdict |
|---|---|---|---|
| Loadings (items) | ≥ 0,70 | 0,641 – 0,918 (1 item limite) | ✓ Satisfaisant |
| Alpha de Cronbach | ≥ 0,70 | 0,839 – 0,909 | ✓ Excellent |
| Fiabilité Composite | ≥ 0,70 | 0,891 – 0,936 | ✓ Excellent |
| AVE (validité convergente) | ≥ 0,50 | 0,591 – 0,789 | ✓ Excellent |
| Fornell-Larcker | √AVE > corr. | Respecté sur tous les construits | ✓ Validé |
| HTMT | < 0,85 – 0,90 | 2 paires à surveiller (≤0,968) | ⚠ Globalement acceptable |
Bilan du modèle structurel
| Indicateur global | Valeur | Évaluation |
|---|---|---|
| R² Intention d’usage | 0,808 | ✓ Substantiel |
| Q² Intention d’usage | 0,791 | ✓ Très élevé |
| SRMR Global | 0,063 | ✓ Excellent fit |
| PLSpredict (4 items INT) | Tous supérieurs au naïf | ✓ Pouvoir prédictif fort |
Tableau 13 — Synthèse des indicateurs globaux du modèle structurel.
Ces résultats indiquent que l’acceptation des robots humanoïdes est avant tout une affaire de perception émotionnelle : le plaisir ressenti lors de l’interaction est le moteur principal de l’intention d’usage. Ce plaisir est lui-même très fortement alimenté par la perception d’attributs humains chez le robot (anthropomorphisme). L’utilité est un prédicteur complémentaire, mais secondaire. Les risques perçus — à l’exception du risque vie privée — n’exercent pas d’influence significative sur l’intention une fois contrôlés les effets des bénéfices perçus, ce qui suggère que dans ce contexte, les émotions positives “court-circuitent” les appréhensions rationnelles.
- (1998). The partial least squares approach to structural equation modeling. In G. A. Marcoulides (Ed.), Modern methods for business research (pp. 295–336). Lawrence Erlbaum Associates.
- (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
- (1992). A power primer. Psychological Bulletin, 112(1), 155–159.
- (1951). Coefficient alpha and the internal structure of tests. Psychometrika, 16(3), 297–334.
- (1979). A paradigm for developing better measures of marketing constructs. Journal of Marketing Research, 16(1), 64–73.
- (1981). Evaluating structural equation models with unobservable variables and measurement error. Journal of Marketing Research, 18(1), 39–50.
- (1975). The predictive sample reuse method with applications. Journal of the American Statistical Association, 70(350), 320–328.
- (2001). Knowledge management: An organizational capabilities perspective. Journal of Management Information Systems, 18(1), 185–214.
- (2019). When to use and how to report the results of PLS-SEM. European Business Review, 31(1), 2–24.
- (2018). Advanced issues in partial least squares structural equation modeling (PLS-SEM). SAGE Publications.
- (2015). A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of the Academy of Marketing Science, 43(1), 115–135.
- (2014). The use of partial least squares path modeling in international marketing. Advances in International Marketing, 20, 277–319.
- (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling, 6(1), 1–55.
- (1978). Psychometric theory (2nd ed.). McGraw-Hill.
- (2007). A caution regarding rules of thumb for variance inflation factors. Quality & Quantity, 41(5), 673–690.
- (2015). SmartPLS 3. SmartPLS GmbH. http://www.smartpls.com
- (2019). Predictive model assessment in PLS-SEM: Guidelines for using PLSpredict. European Journal of Marketing, 53(11), 2322–2347.
- (1974). Cross-validatory choice and assessment of statistical predictions. Journal of the Royal Statistical Society: Series B, 36(2), 111–147.